
一文讲清!免疫组测序技术如何选择起始核酸和建库方法!
发布时间:2023-08-24 15:29 | 点击次数:
艾沐蒽 ImmuHub®免疫组测序平台灵活度极高,可以 DNA 或 RNA 作为模板,搭配不同的文库构建方法来实现免疫组测序,帮助您解读适应性免疫系统的复杂性。
关于如何选择 RNA 还是 DNA,以及建库方法,很多老师初次接触免疫组测序技术研究时都会产生疑问,这重点取决于样本情况和相关研究目的。
本篇将重点介绍如何选择适合免疫组研究的技术方法以及选择的原因。

01 选择 RNA 作为模板的原因
尽管基因组 DNA 和 RNA 均可用于 Immune Profiling,但每个细胞的 mRNA 拷贝数至少比 gDNA 多 10 到 100 倍。研究表明,较高数量的起始 RNA 模板拷贝可显著提高 T 细胞受体的检测水平。

由此数据可看到,相同样本基于 mRNA 的 TCR 测序结果,其 TCR 克隆型种类更多。(数据来源于 Cellecta, Inc.)
2. 基于 RNA 免疫组受体测序均是功能性蛋白序列,与抗原诱导和疾病特异性相关较高
对 mRNA 进行测序揭示了经过剪接和转录后加工的表达受体的序列,因此更有可能产生功能性蛋白质(图 2),且克隆型在不同水平表达受体 mRNA,适应性免疫的激活会诱导抗原特异性克隆型中 TCR 和 BCR 转录显著上调。所以基于 mRNA 的免疫受体库通常会有少量丰富的克隆型主导,其中许多丰富的克隆型可能是抗原诱导的或疾病特异性的。而 DNA 层面更容易检测到非功能性表达的序列。所以当研究 TCR 与抗原疾病相关的研究时更适合用 mRNA。
图 2. TCR DNA 剪切转录、翻译过程
3. 基于 mRNA 的免疫组测序能区分 C 区 Ig 亚型信息
使用基因组 DNA 作为模板的免疫组分析,无法识别 Ig 亚型,因为该亚型上的 V(D)J 和 C 区域被内含子分开(图 3),从而阻止一起被 PCR 扩增出来 C 基因信息。而 mRNA 作为模板,可以避免此问题,结合 5'RACE 扩增方法,能同时获得 C 区信息。
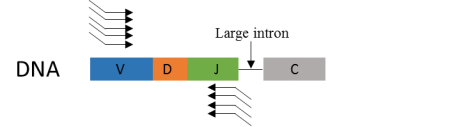
图 3. DNA 层面 VDJC 连接示意图
4. 基于 mRNA 的免疫组扩增,可获得 VDJ 全长信息
Bulk 免疫组测序,使用 mRNA 结合 5'RACE 单对引物方法建库(建库方法介绍详细见后),可获得 VDJ 全长信息,而 DNA 层面不能(详见图 12 所示)。
单细胞 VDJ 测序也都是基于 mRNA 水平开展,同时能获得全长配对信息,也能联合转录组进行联合分析。
5. 基于 RNA 层面开展的免疫组临床诊断和治疗转化应用更多
目前最近有关 TCR-T 开发研究相关也都是基于 RNA 水平开展的,如基于 RNA 测序来检查表达并预测新表位是否会被 MHC 呈递以被 T 细胞识别。

图 4. 参考来源:Jingjing He ,etal. Defined tumor antigen-specific T cells potentiate personalized TCR-T cell therapy and prediction of immunotherapy response
02 选择 DNA 作为模板的原因
一个 gDNA 的拷贝对应一个细胞,适合于需要进行相对定量的检测,如血液肿瘤微小残留病检测(MRD)应用,具体应用可参考艾沐蒽 Seq-MRD®相关介绍。
适用于一些不便提取 RNA,仅能提取 DNA 的样本,如 FFPE 等。DNA 保存相对稳定,不需要逆转录,技术要求低。
综上,除非对于应用于相对定量时需要使用 DNA 作为模板,其它情况,如疾病抗原相关的免疫组、biomarker 应用、TCR-T 免疫治疗开发等应用,建议优先选择均以 RNA 为模板来进行。
大多数免疫分析实验都集中在 TCR 和 BCR 序列的 CDR3 区域。CDR3 区域包含抗原和受体之间相互作用的核心位点,因此变化最大。然而,RNA+5'RACE 全长测序将包括受体的其他区域,包括 CDR1 和 CDR2,它们在抗原-受体结合和/或下游信号传导的亲和力中发挥作用。全长测序还使直接克隆和表达在免疫组库测序研究中鉴定的那些受体变得更加容易。这对于抗体治疗或 T 细胞治疗应用尤为重要。

所以,如果研究仅需分析 CDR3 区,选择多重 PCR 或者 5'RACE 方法均可行,但如需要获得全长序列信息,仅 bulk 的 RNA+5'RACE 建库测序和单细胞测序方法才可实现。
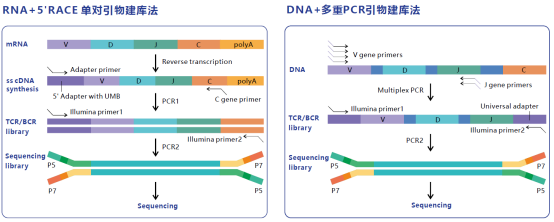
多重 PCR 适用于 DNA 和 RNA 模板,通常由两轮 PCR 组成(如果使用 RNA 作为模板,则在 cDNA 合成之后)。第一轮 PCR 扩增受体基因座,并添加已知序列作为第二轮的启动位点,其中包含测序接头和 index。然而,第一次 PCR 的 3' 端,尤其是 5' 端的引物位点具有显著的高序列多样性,这就需要许多简并引物来扩增不同的 TCR/BCR 序列(见图 6 右)。因此,易引入 PCR 偏差,其中与引物更相似的受体序列被更有效地扩增(图 7)。

另一种方法是 5'RACE(见图 6 左),此方法仅适用于 RNA 作为模板,在 cDNA 合成过程中通过在 5' 端添加已知的 adptor 序列,随后使用此接头序列而不依赖于 TCR 或 BCR cDNA 中的简并引物,这大大降低了 PCR 偏差,不依赖于引物设计,具有更高的目标率。同时,艾沐蒽在逆转录 cDNA 过程中为每个 RNA 添加 UMB 标签,能确保免疫组库概况,反映原始样本中序列情况,而不受 PCR 扩增序列变多的影响,以及 PCR 或测序错误影响。
01 关于 ImmuHub® 5』RACE 单对引物建库方法引入 UMB 对免疫组结果数据的影响
基于 5'RACE 原理,引入 UMB(Unique Molecular Barcode,独立分子条形码)进行文库构建。每个样本检测中,在原始 RNA 模板扩增前加入的 UMB 种类可高达约 1700 万种。这可对后续 PCR 扩增或测序过程中的错误进行有效纠正,还原真实的数据,有如下两个优势:

图 8. 基于 UMB 的纠错

▲ 图 9. UMB 技术修正了 PCR 扩增和测序错误,还原真实的免疫组多样性(蓝bar),避免了假高多样性(红 bar)
2. 准确评估单克隆T细胞的情况
通过计数每种 UMB 的数目,对具有相同 UMB 的序列进行合并处理,可以将因为 PCR 扩增导致的多条相同序列,还原到样本 PCR 扩增前的真实状态,从而能够准确评估单克隆 T 细胞的比例。(单克隆 T 细胞比例是指测序仅测到一个 TCR 分子的比例,有研究表明这与初始 T 细胞成正相关)
而 DNA+多重 PCR 方法中,因未加入 UMB,测到的单克隆 T 细胞比例会偏低,继而影响 TCR 多样性计算(图 10)。


5'RACE 单对引物建库法能够得到包含完整 TCR/BCR,这意味着可以保留完整的 V 基因序列,即可以扩增 VDJ 全长序列,同时又由于是根据 C 区设计引物,还可得到 C 基因信息,如对 BCR 测序,还可得到 IgH isotype 信息。此种方法能够匹配多种不同测序模式,PE150/PE250/PE300 均可。而多重 PCR 方法仅能扩增 CDR3 区。
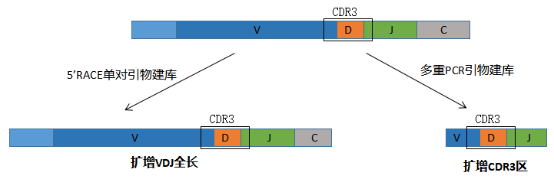
对于扩增的全长序列,可以选择使用 PE150 测序仅分析 CDR3 区信息,也可使用 PE300 测序直接分析得到 VDJ 全长信息。
单细胞测序是采用 5' 接头的通用引物和 TCR/BCR 恒定区 (C 区) 的保守引物进行的进行巢式 PCR,实现高特异性 TCR/BCR 的 V 区 (包含 V、D、J 片段) 序列富集。扩增富集得到的全长 V(D)J 序列大概是 650bp 左右,通过酶切为长短不一的片段,再使用 PE150 测序。
综上,当能同时提取 RNA 或 DNA 时,我们优先选择使用 RNA+5』race 方法建库后,再进行高通量测序可获得更为准确和全面的 TCR/BCR 信息。


部分基于 ImmuHub® 平台发表的学术论文:www.immuquad.com/publications
更多关于 bulk 免疫组测序与单细胞 VDJ 测序区别和如何选择,请关注下次分享。
杭州艾沐蒽生物科技有限公司成立于 2016 年,是国内前沿的专注于免疫基因组学技术的国家高新技术企业。创始人团队来自美国芝加哥大学,在 2010 年开始使用免疫组高通量测序技术开展各种疾病相关研究,于 2016 年通过自主研发,全国率先推出 NGS-MRD 血液肿瘤微小残留病(MRD)检测 Seq-MRD®,并授权泛生子(纳斯达克代码:GTH)使用。同时,公司拥有 Immun-Traq®肿瘤治疗伴随诊断、Immun-Cheq® |T 细胞免疫测评以及 ImmuHub®免疫组测序科研服务产品,并布局有基于 AI 机器学习算法的 T-classifier®疾病早筛、单细胞测序、TCR-T 药物开发等平台管线。公司构建几十项发明专利和软件著作权为核心的自主知识产权体系,为医院临床、生命科学研究、新药开发等提供解决方案和产品。
艾沐蒽专注于通过解码适应性免疫系统来改变疾病的诊断和治疗,并致力于推进免疫驱动医学领域发展。

ImmunoDiagnostics | ImmunoMonitoring
免疫诊断 | 免疫监控
专注于免疫组高通量测序
ImmuHub | Seq-MRD | Immun-Traq
| Immun-Cheq | T-Classifier |TCR-T
Web:www.immuquad.com
Email:Contact@immuquad.com
Tel:0571-81061561
Address:杭州市上城区石桥路196号浙江省农创园4号楼1层